04/03
_ [文字入力] AOUR練習用のGoogle日本語入力ローマ字定義ファイル
AOUR入力中の表示
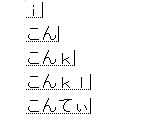

AOUR配列紹介の続きの前にもう1つ。練習中に困っていたことが [BackSpace] の場所が遠いことの他にもう一つありました。それは、入力中の見た目が入力したい文字列と関係しているように思えないこと。
[AOUR配列] Goole日本語入力用の定義ファイルを使って、「コンティニュー」と入力してみたときの例。確かにタイプ数は少ないのですが、「i」とか「kl」とかの途中状態がよく分かりません。ある程度の固まりを入力するまでは己を信じてキーボードも画面も見ない ……いや、きついですって(汗)。
gACT10入力中の表示
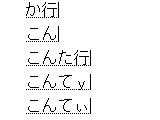

ここを、同じくGoogle日本語入力を使っているDvorak系の [gACT10] はどうなっているのかなと、導入してみました。「コンティニュー」に関しては、「ティ」の2打目以外は同じように入力できました。
おお! 「か行」「てy」のように、今の状態が何で次にどうすれば良いのかがよく分かります。もちろん母音の配置を覚えなければと言うことは変わりませんが、子音の間違いに気付かないまま入力を続けると言うことがかなり抑えられます。
練習用として考えると
しかし、見やすさの代わりに欠点もあります。今のGoogle日本語入力では、文字を消すのが入力したキーの単位でなく表示された文字の単位。なのでカ行を入力するつもりで中指中段をうっかり触り「さ行」と表示されると、この取消に [BackSpace] を2回押す必要があります。誤入力が少ない人なら大丈夫でしょうけれども、指が覚える前に何度も書いて何度も消し手を繰り返しているときにはちょっと、という感じがします。
AOUR練習用にガイドを入れてみた


と言うわけで、AOUR練習用にgACT10のような途中状態のガイドを入れてみました。 > AOUR110103_with_guide.txt (UTF-8)
これなら子音の入力間違いに、画面を見て気づけそうです。
- 確定状態はすべてひらがな、途中状態はすべてカタカナ1文字にしました。[BackSpace] 1回で戻れます。カタカナが2文字表示される場合は、その組み合わせはAOURで定義されていません。
- カタカナ1文字の選び方は、「カ行」などの普通の五十音のものは子音+「ア」で終わるもの、「キャ行」のような拗音付きは子音+「イ」で終わるもの、その他は適当にしています。
- 「ひゃ」の2打目が右手人差し指でも右手薬指でも3打目を同じように打てるところに対し、定義をまとめています。同じカタカナを表示しています。
- できるだけ本家に合わせたつもりですが、意図しない配列の違いや Google日本語入力上での不都合が混じっている可能性があります。
- 「vu」はGoogle日本語入力の標準設定では「う゛」でなく「ヴ(ひらがな1文字)」になっています。確定後のひらがなでもカタカナ「ヴ」に見えて分かりにくいという理由で、AOUR本家同様「う゛」にしています。
対応しているガイド文字列一覧です。読みやすくはありませんけれど、一応。
| あ〜か | さ〜た | な〜は | ま〜わ | ||||
|---|---|---|---|---|---|---|---|
| p | ァ | ; | サ | l | ナ | m | マ |
| we | ウ | e | ザ | lj | ニ | m. | ミ |
| q | ヴ | b | シ | j | ハ | mm | ミ |
| i | カ | c | ジ | n | バ | pt | ャ |
| u | ガ | k | タ | r | パ | t | ヤ |
| iu | キ | h | ダ | jj | ヒ | o | ラ |
| uo | ギ | v | チ | jl | ヒ | ou | リ |
| uu | ギ | hj | ヂ | n. | ビ | pw | ヮ |
| ii | ク | hl | ヂ | nm | ビ | w | ワ |
| ki | ツ | ru | ピ | ||||
| kl | テ | y | フ | ||||
| hh | デ | ||||||
Google日本語入力定義ファイルの作り方
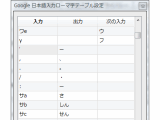
Google日本語入力のローマ字定義は、「入力」「出力」「次の入力」の3つを並べたテーブルでできています。「次の入力」がATOKには無いし、何に使うのだろう?? と思っていました。この次の入力、似た定義をまとめる効果や、途中状態の文字列表示に使えます。
さらに「っ」の特殊な条件分岐がいらなくなるという効果もあります。たとえば「さっっぱり」と入力する際。ATOKでは「同じ子音が連続すると『っ』を書く」というルールにしています。もしこの特殊規則がなく「ppa = っぱ」「pppa = っっぱ」のようにローマ字表の中に織り込むとすると、表が大きくなりすぎて大変な事になります。Google日本語入力だとそんなことをしなくても普通のローマ字定義で扱えます。
| キー | 入力の組 | 出力 | 次の入力 |
|---|---|---|---|
| s | s | s | |
| a | sa | さ | |
| p | p | p | |
| p | pp | っ | p |
| p | pp | っ | p |
| a | pa | ぱ |
ああなんてStateパターン、とプログラマな方なら思うかも。
AOUR練習用の定義ファイルはこの辺りの話は全然関係なく、単に「mm」などの子音組み合わせに別名を付けただけです。
最後に
Google日本語入力でこれを使って練習して、画面を見なくても大丈夫になった頃に本家定義ファイルに戻したり、ATOKを使ってみるというのが良いのではないかと思います。
……ATOKのローマ字カスタマイズがずっと今のままなら、メインをGoogle日本語入力に乗り換えても言いかもと考えてしまうくらい、このローマ字カスタマイズ機能は強力です。
_ [文字入力] ローマ字練習用のGoogle日本語入力ローマ字定義ファイル
AOUR向きに作れたのだから、Google日本語入力の物も書き換えられるのではと試してみました。Google日本語入力 1.0.556.0 の定義ファイルから作成しています。 > googleime556_with_guide.txt (UTF-8)
作り方の方向性はAOURと同じです。
普通の入力


ガイド付き入力


分かりやすいかどうかは別として、同じように入力した時、カタカナで補助情報を確認できます。
制限
- 状態が1文字ではどうしても足りず、比較的マイナーと思われる方を2文字にしています。
- 「n」には対応していません。「ナ行」なのか「ん」なのか分からないためです。
- 「c」にも対応していません。「かしくせこ」という謎めいた配列なのと、普通「ch」など組み合わせて使うだろうと思ったためです。
- 「v」は「ヴ」のひらがなもカタカナに見え、小さな混乱があるかも知れません。
- 「z」を「ザ行」でなく「←↓↑→」などの記号キーとして使うときも、「ザ」と表示されます。
ガイド文字一覧
| あ〜さ | た | な〜は | ま〜わ | ||||
|---|---|---|---|---|---|---|---|
| l | ァ | t | タ | ny | ニ | m | マ |
| x | ァ | d | ダ | h | ハ | my | ミ |
| wh | ウ | cy | チ | b | バ | ly | ャ |
| v | ヴ | ty | チ | p | パ | xy | ャ |
| vy | ヴャ | dy | ヂ | hy | ヒ | y | ヤ |
| lk | ヵ | ch | チャ | by | ビ | r | ラ |
| xk | ヵ | lt | ッ | py | ピ | ry | リ |
| k | カ | xt | ッ | f | フ | lw | ヮ |
| g | ガ | ts | ツ | hw | フィ | xw | ヮ |
| ky | キ | wwh | ッウ | fy | フャ | w | ワ |
| gy | ギ | ww | ッワ | hwy | フュ | wy | ヰ |
| kw | ク | wwy | ッヰ | ||||
| gw | グ | th | テ | ||||
| q | クァ | dh | デ | ||||
| s | サ | t' | ティ | ||||
| z | ザ | d' | ディ | ||||
| sy | シ | t'y | テュ | ||||
| j | ジ | d'y | デュ | ||||
| sh | シャ | tw | ト | ||||
| jy | ジャ | dw | ド | ||||
かなり細かい定義がされています。特に「ww」が絡むところにびっくり。
「kw = ク」と「q = クァ」はどちらも「クァ行」です。しかし「kwu」はなくて「qu = く」はあります。いやはや。
ぶっちゃけ
このテーブルを使うと、「th = ティ行」に何か意味があるということが入力中に分かります。しかしそれだけ。定義を覚えていないと使えません。それにカ行とか普通の物は「k」で十分で、「カ」なんて出てくると余計に分からなくなるでしょう。
こういうさっぱり役に立たないものを4/1に公開すれば良かった……。書き終わった後に気付いたわけでした(汗)。
おまけ: ガイドを付けるスクリプト
AOUR, 標準定義ファイルの変換はこのスクリプトで行いました。変換後に調整せずそのまま公開しています。
- 元の Google日本語入力のローマ字定義ファイルを用意します
- ファイルの上側に独自定義を書き足します
- 変換スクリプト (Ruby1.9.1で動作確認) でこのファイルを読み込みます
- ガイド付きのローマ字定義ファイルが出力されます
b バ by ビ ch チャ cy チ
# encoding: UTF-8 Encoding.default_external = Encoding::UTF_8 class Roman attr_reader :key, :value, :state def initialize(key, value, state) @key = key @value = value @state = state end def to_s "#{@key}\t#{@value}" + (@state ? "\t#{@state}" : "") end end set = {} ARGF.each do |line| ary = line.chomp.split("\t", -1) if ary.size < 2 puts line next end queue = ary[0] key, value, state = "", ary[1], ary[2] state = set[state].state if set.key? state until queue.empty? key, queue = key + queue[0], queue[1..-1] key = set[key].state if (set.key?(key) && set[key].value.empty?) end next if (key.nil? || set.key?(key) || key == state) set[key] = Roman.new(key, value, state) puts set[key] end
さっぱりテストしていません。最後から4行目の出力しない行判定にやっつけ感が漂っていたり。他の文字配列ではたぶん巧く動かないと思います。

